
- Single responsibility principle
- Open/closed principle
- Liskov substitution principle
- Interface segregation principle
- Dependency inversion principle
Wujek Bob wrócił wspomnieniami do końca lat 70 XX wieku - czasu kiedy wpadł na pomysł odwrócenia zależności. Była to epoka procesorów 8085 z 32kB RAM-u i 32kB ROM-u. Wyobrażacie to sobie?!
 |
| Wujek bob nawet to pamięta |
O co chodzi z tym odwracaniem?
Żeby to zrozumieć przyda nam się jakiś trywialny (i dość mierny) przykład - DI(los). Odwróciliśmy sobie SOLID i powstało coś w miarę sensownego - Dependency Inversion los, który nas w tym odcinku interesuje najbardziej. Tak to już jest, że czasami warto na coś spojrzeć z drugiej strony. Wiele technik i praktyk powstało dzięki takiemu założeniu (np. TDD) i podobnie jest z DI. Zejdźmy trochę głębiej w rozważaniach. Wujek wyróżnił 2 rodzaje zależności: run time oraz compile time. Zasada DI dotyczy tej drugiej - zależności czasu kompilacji.
Cash baby, cash...
W językach statycznie typowanych (takich jak Java, C#, C, C++) koszt zależności kodu źródłowego (typu compile time) jest znaczny. Kompilator musi poznać szczegóły modułów, do których się odnosimy za pomocą nazw w kodzie. Często w takim wypadku musi skompilować powtórnie wszystkie moduły zależne. Kiedyś kompilacja systemu mogła trwać nawet godziny. Dzisiaj w zasadzie moglibyśmy stwierdzić, że to nie problem - w końcu kompilatory czy to Javy czy C# są już naprawdę sprawne. Jednak ciągle czas kompilacji dużego systemu może być denerwujący - nawet jeśli trwa tylko pół minuty. Co innego jeśli weźmiemy na stół wdrożenie. Załóżmy, że zmiana w jednej klasie powoduje konieczność przebudowy wielu modułów, wtedy wszystkie musimy zdeployować - chore! Moim zdaniem jednak znacznie gorsze są utrudnienia z samym developowaniem. Załóżmy, że nad systemem pracuje większy zespół podzielony w celu rozwoju różnych komponentów. Jeśli zmiany jednego zespołu powodują konieczność kompilacji innego zespołu to mamy do czynienia z efektem opisywanym krótko - aczkolwiek zacnie - przez Pawła Włodarskiego - syf i zniszczenie.
Odwracamy...
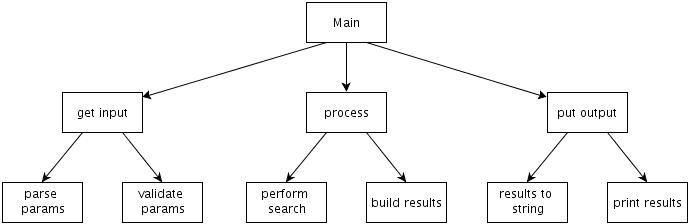
Warto wiedzieć co jest podstawą do idei odwracania zależności. Wujek Bob wskazuje na projektowanie strukturalne (metoda top-down). Sposób zakłada rozpoczęcie dekompozycji problemu od głównej funkcji - main. Następnie projektuje się podprogramy, które mają być wywoływane przez main w celu realizacji pod-zadania. Podobnie każdy podprogram zostaje podzielony na jeszcze mniejsze podprogramy itd, aż zaprojektujemy wszystkie podprogramy konieczne do realizacji celu. Mając taki projekcik możemy zacząć pisać kod (yeah:D). Problem z tym podejściem jest taki, że zależności czasu kompilacji są dokładnie takie same jak czasu wykonania (w trakcie kompilacji wiemy, które kawałki kodu możemy wołać i potrzebujemy znać szczegóły ich implementacji).
 |
| Projektowanie strukturalne (top-down) |
{kind=link}


{kind=link}
 |
| Publika się obudziła - w końcu dostaliśmy jakiegoś koda... |
SOLID by example: Flash talk Łukasza Strobina
Po zmęczonym już nieco wujku Bobie przyszedł czas na Łukasza Strobina z Transition Technologies, który zaprezentował zasady SOLID w przykładach z kodem. Dla każdej z zasad Łukasz wskazał kod naruszający jej zasady oraz rozwiązanie. W trakcie nawiązała się fajna dyskusja, padło kilka ciekawych stwierdzeń. Jedno wydaje mi się bardzo celne, że najważniejszy jest zdrowy rozsądek, czyli narzędzie, które pozwala świadomie łamać zasady.
Już za tydzień, 26 czerwca, kolejne spotkanie z Robertem Martinem dzięki firmie Seamless. Na ostatnim przed wakacjami spotkaniu wujek zaprezentuje case study zasad SOLID. Więcej o spotkaniu na meetupie. Zapraszamy, będzie jazdaaa.
PS. Dzięki za Pawłowi Włodarskiemu za zdjęcia.
"Była to epoka procesorów 8085 z 32MB Ramu i 32MB Romu. Wyobrażacie to sobie?!"
ReplyDeleteOczywiście chodzi o 32 KB RAM-u i 32 KB ROM-u. To sobie jeszcze ciężej wyobrazić :)
Dzięki Michał za poprawkę.
ReplyDelete